调试¶
课程目标:¶
调试是 Linux 内核开发的一个重要部分。在用户空间中,我们可以依靠内核的支持,轻松地停止进程并使用 gdb 来检查它们的行为。在内核中,为了使用 gdb,我们需要使用像 QEMU 或基于 JTAG 的硬件接口这样的虚拟化程序,然而这些并不总是可用的。Linux 内核提供了一组有用的工具和调试选项,用于调查异常行为。
在本课程中,我们将学习以下内容:
- 解码 oops/panic
- 列表调试
- 内存调试
- 锁调试
- 性能分析
解码 oops/panic¶
oops 是内核在自身内部检测到的一种不一致状态。在检测到 oops后,Linux 内核会终止有问题的进程,打印可以帮助调试问题的信息,并继续执行,但可靠性有限。
让我们考虑以下 Linux 内核模块:
static noinline void do_oops(void)
{
*(int*)0x42 = 'a';
}
static int so2_oops_init(void)
{
pr_info("oops_init\n");
do_oops();
return 0;
}
static void so2_oops_exit(void)
{
pr_info("oops exit\n");
}
module_init(so2_oops_init);
module_exit(so2_oops_exit);
请注意,''do_oops'' 函数试图写入一个无效的内存地址。因为内核无法找到合适的物理页面来进行写操作,它会终止在 ''do_oops'' 运行上下文中的 insmod 任务。然后,它会打印以下 oops 消息:
root@qemux86:~/skels/debugging/oops# insmod oops.ko BUG: unable to handle kernel NULL pointer dereference at 00000042 IP: do_oops+0x8/0x10 [oops] *pde = 00000000 Oops: 0002 [#1] SMP Modules linked in: oops(O+) CPU: 0 PID: 234 Comm: insmod Tainted: G O 4.15.0+ #3 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Ubuntu-1.8.2-1ubuntu1 04/01/2014 EIP: do_oops+0x8/0x10 [oops] EFLAGS: 00000292 CPU: 0 EAX: 00000061 EBX: 00000000 ECX: c7ed3584 EDX: c7ece8dc ESI: c716c908 EDI: c8816010 EBP: c7257df0 ESP: c7257df0 DS: 007b ES: 007b FS: 00d8 GS: 0033 SS: 0068 CR0: 80050033 CR2: 00000042 CR3: 0785f000 CR4: 00000690 Call Trace: so2_oops_init+0x17/0x20 [oops] do_one_initcall+0x37/0x170 ? cache_alloc_debugcheck_after.isra.19+0x15f/0x2f0 ? __might_sleep+0x32/0x90 ? trace_hardirqs_on_caller+0x11c/0x1a0 ? do_init_module+0x17/0x1c2 ? kmem_cache_alloc+0xa4/0x1e0 ? do_init_module+0x17/0x1c2 do_init_module+0x46/0x1c2 load_module+0x1f45/0x2380 SyS_init_module+0xe5/0x100 do_int80_syscall_32+0x61/0x190 entry_INT80_32+0x2f/0x2f EIP: 0x44902cc2 EFLAGS: 00000206 CPU: 0 EAX: ffffffda EBX: 08afb050 ECX: 0000eef4 EDX: 08afb008 ESI: 00000000 EDI: bf914dbc EBP: 00000000 ESP: bf914c1c DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 007b Code: <a3> 42 00 00 00 5d c3 90 55 89 e5 83 ec 04 c7 04 24 24 70 81 c8 e8 EIP: do_oops+0x8/0x10 [oops] SS:ESP: 0068:c7257df0 CR2: 0000000000000042 ---[ end trace 011848be72f8bb42 ]--- Killed
oops 包含有关导致故障的 IP、寄存器状态、进程和发生故障的 CPU 的信息,如下所示:
root@qemux86:~/skels/debugging/oops# insmod oops.ko
BUG: unable to handle kernel NULL pointer dereference at 00000042
IP: do_oops+0x8/0x10 [oops]
*pde = 00000000
Oops: 0002 [#1] SMP
Modules linked in: oops(O+)
CPU: 0 PID: 234 Comm: insmod Tainted: G O 4.15.0+ #3
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Ubuntu-1.8.2-1ubuntu1 04/01/2014
EIP: do_oops+0x8/0x10 [oops]
CR0: 80050033 CR2: 00000042 CR3: 0785f000 CR4: 00000690
EIP: 0x44902cc2
EFLAGS: 00000206 CPU: 0
EAX: ffffffda EBX: 08afb050 ECX: 0000eef4 EDX: 08afb008
ESI: 00000000 EDI: bf914dbc EBP: 00000000 ESP: bf914c1c
DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 007b
Code: <a3> 42 00 00 00 5d c3 90 55 89 e5 83 ec 04 c7 04 24 24 70 81 c8 e8
Killed
oops 还可以提供故障发生前调用的函数的堆栈跟踪信息:
root@qemux86:~/skels/debugging/oops# insmod oops.ko
BUG: unable to handle kernel NULL pointer dereference at 00000042
Call Trace:
so2_oops_init+0x17/0x20 [oops]
do_one_initcall+0x37/0x170
? cache_alloc_debugcheck_after.isra.19+0x15f/0x2f0
? __might_sleep+0x32/0x90
? trace_hardirqs_on_caller+0x11c/0x1a0
? do_init_module+0x17/0x1c2
? kmem_cache_alloc+0xa4/0x1e0
? do_init_module+0x17/0x1c2
do_init_module+0x46/0x1c2
load_module+0x1f45/0x2380
SyS_init_module+0xe5/0x100
do_int80_syscall_32+0x61/0x190
entry_INT80_32+0x2f/0x2f
Killed
解码 oops¶
- CONFIG_DEBUG_INFO
- addr2line
- gdb
- objdump -dSr
addr2line¶
addr2line 将地址转换为文件名和行号。给定一个可执行文件中的地址,它使用调试信息来确定与之关联的文件名和行号。
模块在动态地址上加载,但是它们从 0 开始编译作为基地址。因此,为了找到给定动态地址的行号,我们需要知道模块的加载地址。
$ addr2line -e oops.o 0x08
$ skels/debugging/oops/oops.c:5
$ # 0x08 是 oops.ko 模块中有问题的指令的偏移量
objdump¶
类似地,我们可以使用 objdump 确定有问题的行:
$ cat /proc/modules
oops 20480 1 - Loading 0xc8816000 (O+)
$ objdump -dS --adjust-vma=0xc8816000 oops.ko
c8816000: b8 61 00 00 00 mov $0x61,%eax
static noinline void do_oops(void)
{
c8816005: 55 push %ebp
c8816006: 89 e5 mov %esp,%ebp
*(int*)0x42 = 'a';
c8816008: a3 42 00 00 00 mov %eax,0x42
gdb¶
$ gdb ./vmlinux
(gdb) list *(do_panic+0x8)
0xc1244138 is in do_panic (lib/test_panic.c:8).
3
4 static struct timer_list panic_timer;
5
6 static void do_panic(struct timer_list *unused)
7 {
8 *(int*)0x42 = 'a';
9 }
10
11 static int so2_panic_init(void)
内核崩溃¶
内核崩溃(kernel panic)是一种特殊类型的 oops,其中内核无法继续执行。例如,如果上述的 do_oops 函数是在中断上下文中调用的,内核将不知道如何终止它,并决定最好的方式是崩溃内核并停止执行。
以下是一个会导致内核崩溃的示例代码:
static struct timer_list panic_timer;
static void do_panic(struct timer_list *unused)
{
*(int*)0x42 = 'a';
}
static int so2_panic_init(void)
{
pr_info("panic_init\n");
timer_setup(&panic_timer, do_panic, 0);
mod_timer(&panic_timer, jiffies + 2 * HZ);
return 0;
}
加载该模块将生成以下内核崩溃消息:
root@qemux86:~/skels/debugging/panic# insmod panic.ko
panic: loading out-of-tree module taints kernel.
panic_init
root@qemux86:~/skels/debugging/panic# BUG: unable to handle kernel NULL pointer dereference at 00000042
IP: do_panic+0x8/0x10 [panic]
*pde = 00000000
Oops: 0002 [#1] SMP
Modules linked in: panic(O)
CPU: 0 PID: 0 Comm: swapper/0 Tainted: G O 4.15.0+ #19
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Ubuntu-1.8.2-1ubuntu1 04/01/2014
EIP: do_panic+0x8/0x10 [panic]
EFLAGS: 00010246 CPU: 0
EAX: 00000061 EBX: 00000101 ECX: 000002d8 EDX: 00000000
ESI: c8817000 EDI: c8819200 EBP: c780ff34 ESP: c780ff34
DS: 007b ES: 007b FS: 00d8 GS: 0000 SS: 0068
CR0: 80050033 CR2: 00000042 CR3: 0716b000 CR4: 00000690
Call Trace:
<SOFTIRQ>
call_timer_fn+0x63/0xf0
? process_timeout+0x10/0x10
run_timer_softirq+0x14f/0x170
? 0xc8817000
? trace_hardirqs_on_caller+0x9b/0x1a0
__do_softirq+0xde/0x1f2
? __irqentry_text_end+0x6/0x6
do_softirq_own_stack+0x57/0x70
</SOFTIRQ>
irq_exit+0x7d/0x90
smp_apic_timer_interrupt+0x4f/0x90
? trace_hardirqs_off_thunk+0xc/0x1d
apic_timer_interrupt+0x3a/0x40
EIP: default_idle+0xa/0x10
EFLAGS: 00000246 CPU: 0
EAX: c15c97c0 EBX: 00000000 ECX: 00000000 EDX: 00000001
ESI: 00000000 EDI: 00000000 EBP: c15c3f48 ESP: c15c3f48
DS: 007b ES: 007b FS: 00d8 GS: 0000 SS: 0068
arch_cpu_idle+0x9/0x10
default_idle_call+0x19/0x30
do_idle+0x105/0x180
cpu_startup_entry+0x25/0x30
rest_init+0x1e3/0x1f0
start_kernel+0x305/0x30a
i386_start_kernel+0x95/0x99
startup_32_smp+0x15f/0x164
Code: <a3> 42 00 00 00 5d c3 90 55 89 e5 83 ec 08 c7 04 24 24 80 81 c8 e8
EIP: do_panic+0x8/0x10 [panic] SS:ESP: 0068:c780ff34
CR2: 0000000000000042
---[ end trace 77f49f83f2e42f91 ]---
Kernel panic - not syncing: Fatal exception in interrupt
Kernel Offset: disabled
---[ end Kernel panic - not syncing: Fatal exception in interrupt
列表调试¶
为了捕获对未初始化元素的访问,内核使用毒药魔法值。
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = (struct list_head*)LIST_POISON1;
entry->prev = (struct list_head*)LIST_POISON2;
}
BUG: unable to handle kernel NULL pointer dereference at 00000100
IP: crush+0x80/0xb0 [list]
内存调试¶
有多种用于内存调试的工具:
- SLAB/SLUB 调试
- KASAN
- kmemcheck
- DEBUG_PAGEALLOC
SLAB 调试¶
SLAB 调试使用内存毒药技术来检测 SLAB/SUB 分配器中的多种内存错误。
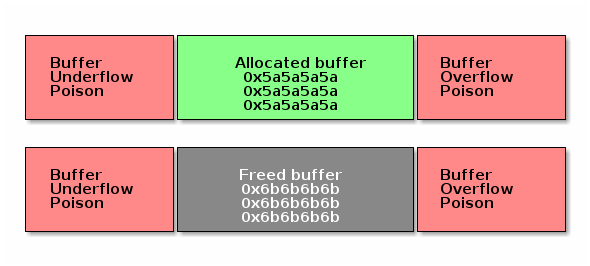
分配的缓冲区使用填充了特殊标记的内存进行保护。当对缓冲区进行其他内存管理操作时(例如,释放缓冲区时),稍后会检测到对缓冲区的任何相邻写操作。
在缓冲区分配时,缓冲区还被填充了一个特殊值,以便在初始化之前检测到对缓冲区的访问(例如,如果缓冲区保存指针)。该值不太可能是有效地址,以在访问时触发内核错误。
在释放缓冲区时,也使用类似的技术:缓冲区被填充了另一个特殊值,如果在内存释放后仍然访问指针,则会触发内核错误。在这种情况下,分配器在下次分配缓冲区时还会检查缓冲区是否被修改。
下图概述了 SLAB/SLUB 毒药技术的工作方式:
- CONFIG_DEBUG_SLAB
- 基于毒药的内存调试器
使用前未初始化错误的示例:
BUG: unable to handle kernel paging request at 5a5a5a5a
IP: [<c1225063>] __list_del_entry+0x37/0x71
…
Call Trace:
[<c12250a8>] list_del+0xb/0x1b
[<f1de81a2>] use_before_init+0x31/0x38 [crusher]
[<f1de8265>] crush_it+0x38/0xa9 [crusher]
[<f1de82de>] init_module+0x8/0xa [crusher]
[<c1001072>] do_one_initcall+0x72/0x119
[<f1de82d6>] ? crush_it+0xa9/0xa9 [crusher]
[<c106b8ae>] sys_init_module+0xc8d/0xe77
[<c14d7d18>] syscall_call+0x7/0xb
noinline void use_before_init(void)
{
struct list_m *m = kmalloc(sizeof(*m), GFP_KERNEL);
printk("%s\n", __func__);
list_del(&m->lh);
}
释放后使用错误示例:
BUG: unable to handle kernel paging request at 6b6b6b6b
IP: [<c1225063>] __list_del_entry+0x37/0x71
…
Call Trace:
[<c12250a8>] list_del+0xb/0x1b
[<f4c6816a>] use_after_free+0x38/0x3f [crusher]
[<f4c6827f>] crush_it+0x52/0xa9 [crusher]
[<f4c682de>] init_module+0x8/0xa [crusher]
[<c1001072>] do_one_initcall+0x72/0x119
[<f4c682d6>] ? crush_it+0xa9/0xa9 [crusher]
[<c106b8ae>] sys_init_module+0xc8d/0xe77
[<c14d7d18>] syscall_call+0x7/0xb
noinline void use_after_free(void)
{
struct list_m *m = kmalloc(sizeof(*m), GFP_KERNEL);
printk("%s\n", __func__);
kfree(m);
list_del(&m->lh);
}
另一个释放后使用错误的示例如下所示。请注意,这次错误在下次分配时被检测到。
# insmod /system/lib/modules/crusher.ko test=use_before_init
Slab corruption: size-4096 start=ed612000, len=4096
000: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 6b 6b
noinline void use_after_free2(void)
{
char *b = kmalloc(3000, GFP_KERNEL);
kfree(b);
memset(b, 0, 30);
b = kmalloc(3000, GFP_KERNEL);
kfree(b);
}
最后,这是一个缓冲区溢出错误的例子:
slab error in verify_redzone_free(): cache `dummy': memory outside object was overwritten
Pid: 1282, comm: insmod Not tainted 3.0.16-mid10-00007-ga4a6b62-dirty #70
Call Trace:
[<c10cc1de>] __slab_error+0x17/0x1c
[<c10cc7ca>] __cache_free+0x12c/0x317
[<c10ccaba>] kmem_cache_free+0x2b/0xaf
[<f27f1138>] buffer_overflow+0x4c/0x57 [crusher]
[<f27f12aa>] crush_it+0x6c/0xa9 [crusher]
[<f27f12ef>] init_module+0x8/0xd [crusher]
[<c1001072>] do_one_initcall+0x72/0x119
[<c106b8ae>] sys_init_module+0xc8d/0xe77
[<c14d7d18>] syscall_call+0x7/0xb
eb002bf8: redzone 1:0xd84156c5635688c0, redzone 2:0x0
noinline void buffer_overflow(void)
{
struct kmem_cache *km = kmem_cache_create("dummy", 3000, 0, 0, NULL);
char *b = kmem_cache_alloc(km, GFP_KERNEL);
printk("%s\n", __func__);
memset(b, 0, 3016);
kmem_cache_free(km, b);
}
DEBUG_PAGEALLOC¶
- 在页面级别上工作的内存调试器
- 通过以下方式检测无效访问:
- 使用毒药字节模式填充页面,并在重新分配时检查模式
- 从内核空间取消映射已释放的页面(仅适用于少数体系结构)
KASan¶
KASan 是一种动态内存错误检测器,旨在查找“释放后使用”和“越界访问”错误。
KASAN 的主要思想是使用阴影内存记录每个字节的内存是否可以安全访问,并使用编译器的插桩在每次内存访问时检查阴影内存。
地址污点分析器使用 1 字节的阴影内存来跟踪 8 字节的内核地址空间。它使用 0-7 来编码八字节区域开头连续有效字节的数量。
有关更多信息,请参阅 内核地址污点分析器(KASAN),并查看 lib/test_kasan.c 以了解 KASan 可以检测到的问题示例。
- 动态内存错误检测器
- 查找“释放后使用”或越界访问错误
- 使用阴影内存跟踪内存操作
- lib/test_kasan.c
KASan vs DEBUG_PAGEALLOC¶
KASan 比 DEBUG_PAGEALLOC 慢,但 KASan 可以在子页面粒度级别上工作,因此能够发现更多的错误。
KASan vs SLUB_DEBUG¶
- SLUB_DEBUG 的开销较低。
- SLUB_DEBUG 在大多数情况下无法检测到错误的读取,而 KASan 可以同时检测到读取和写入。
- 在某些情况下(例如,红区覆盖),SLUB_DEBUG 仅在对象分配/释放时检测到错误。KASan 在临近错误发生前捕捉错误,因此我们可以知道第一次错误读取/写入的确切位置。
Kmemleak¶
Kmemleak 提供了一种检测内核内存泄漏的方法,该方法类似于跟踪垃圾收集器。由于在 C 语言中无法跟踪指针,kmemleak 扫描内核堆栈以及动态和静态内核内存,查找指向分配缓冲区的指针。如果没有指向缓冲区的指针,则认为该缓冲区泄漏。以下是使用 kmemleak 的基本步骤,了解更多信息请参阅 内核内存泄漏检测器。
- 启用内核配置: CONFIG_DEBUG_KMEMLEAK
- 设置: mount -t debugfs nodev /sys/kernel/debug
- 触发内存扫描: echo scan > /sys/kernel/debug/kmemleak
- 显示内存泄漏: cat /sys/kernel/debug/kmemleak
- 清除所有可能的泄漏: echo clear > /sys/kernel/debug/kmemleak
作为示例,让我们看一下以下简单模块:
static int leak_init(void)
{
pr_info("%s\n", __func__);
(void)kmalloc(16, GFP_KERNEL);
return 0;
}
MODULE_LICENSE("GPL v2");
module_init(leak_init);
加载模块并触发 kmemleak 扫描将生成以下报告:
root@qemux86:~# insmod skels/debugging/leak/leak.ko
leak: loading out-of-tree module taints kernel.
leak_init
root@qemux86:~# echo scan > /sys/kernel/debug/kmemleak
root@qemux86:~# echo scan > /sys/kernel/debug/kmemleak
kmemleak: 1 new suspected memory leaks (see /sys/kernel/debug/kmemleak)
root@qemux86:~# cat /sys/kernel/debug/kmemleak
unreferenced object 0xd7871500 (size 32):
comm "insmod", pid 237, jiffies 4294902108 (age 24.628s)
hex dump (first 32 bytes):
5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a ZZZZZZZZZZZZZZZZ
5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a 5a a5 ZZZZZZZZZZZZZZZ.
backtrace:
[<(ptrval)>] kmem_cache_alloc_trace+0x163/0x310
[<(ptrval)>] leak_init+0x2f/0x1000 [leak]
[<(ptrval)>] do_one_initcall+0x57/0x2e0
[<(ptrval)>] do_init_module+0x4b/0x1be
[<(ptrval)>] load_module+0x201a/0x2590
[<(ptrval)>] sys_init_module+0xfd/0x120
[<(ptrval)>] do_int80_syscall_32+0x6a/0x1a0
注解
请注意,我们无需卸载模块就能检测到内存泄漏,因为 kmemleak 会检测到分配的缓冲区不再可达。
Lockdep 检查器¶
- CONFIG_DEBUG_LOCKDEP
- 检测锁反转、循环依赖、锁的错误使用(包括中断上下文)
- 维护锁类之间的依赖关系,而不是个别锁
- 每个场景只检查一次并进行哈希处理
让我们用以下运行两个内核线程的内核模块为例:
static noinline int thread_a(void *unused)
{
mutex_lock(&a); pr_info("%s acquired A\n", __func__);
mutex_lock(&b); pr_info("%s acquired B\n", __func__);
mutex_unlock(&b);
mutex_unlock(&a);
return 0;
}
static noinline int thread_b(void *unused)
{
mutex_lock(&b); pr_info("%s acquired B\n", __func__);
mutex_lock(&a); pr_info("%s acquired A\n", __func__);
mutex_unlock(&a);
mutex_unlock(&b);
return 0;
}
加载此模块并启用 lockdep 检查器将生成以下内核日志:
thread_a acquired A
thread_a acquired B
thread_b acquired B
======================================================
WARNING: possible circular locking dependency detected
4.19.0+ #4 Tainted: G O
------------------------------------------------------
thread_b/238 is trying to acquire lock:
(ptrval) (a){+.+.}, at: thread_b+0x48/0x90 [locking]
but task is already holding lock:
(ptrval) (b){+.+.}, at: thread_b+0x27/0x90 [locking]
which lock already depends on the new lock.
正如你所看到的,尽管死锁条件没有触发(因为线程 A 在线程 B 开始执行之前未完成执行),但 lockdep 检查器识别出了潜在的死锁情况。
Lockdep 检查器将提供更多信息,以帮助确定是什么导致了死锁,例如依赖链:
the existing dependency chain (in reverse order) is:
-> #1 (b){+.+.}:
__mutex_lock+0x60/0x830
mutex_lock_nested+0x20/0x30
thread_a+0x48/0x90 [locking]
kthread+0xeb/0x100
ret_from_fork+0x2e/0x38
-> #0 (a){+.+.}:
lock_acquire+0x93/0x190
__mutex_lock+0x60/0x830
mutex_lock_nested+0x20/0x30
thread_b+0x48/0x90 [locking]
kthread+0xeb/0x100
ret_from_fork+0x2e/0x38
甚至还有一种不安全的加锁场景:
其他可能帮助我们调试的信息:
可能的不安全加锁场景:
CPU0 CPU1
---- ----
lock(b);
lock(a);
lock(b);
lock(a);
*** 死锁 ***
Lockdep 检查器检测到的另一个不安全加锁问题的示例是来自中断上下文的不安全加锁。让我们考虑以下内核模块:
static DEFINE_SPINLOCK(lock);
static void timerfn(struct timer_list *unused)
{
pr_info("%s acquiring lock\n", __func__);
spin_lock(&lock); pr_info("%s acquired lock\n", __func__);
spin_unlock(&lock); pr_info("%s released lock\n", __func__);
}
static DEFINE_TIMER(timer, timerfn);
int init_module(void)
{
mod_timer(&timer, jiffies);
pr_info("%s acquiring lock\n", __func__);
spin_lock(&lock); pr_info("%s acquired lock\n", __func__);
spin_unlock(&lock); pr_info("%s released lock\n", __func__);
return 0;
}
与前一个案例类似,加载该模块将触发 lockdep 警告:
init_module acquiring lock
init_module acquired lock
init_module released lock
timerfn acquiring lock
================================
WARNING: inconsistent lock state
4.19.0+ #4 Tainted: G O
--------------------------------
inconsistent {SOFTIRQ-ON-W} -> {IN-SOFTIRQ-W} usage.
ksoftirqd/0/9 [HC0[0]:SC1[1]:HE1:SE0] takes:
(ptrval) (lock#4){+.?.}, at: timerfn+0x25/0x60 [locking2]
{SOFTIRQ-ON-W} state was registered at:
lock_acquire+0x93/0x190
_raw_spin_lock+0x39/0x50
init_module+0x35/0x70 [locking2]
do_one_initcall+0x57/0x2e0
do_init_module+0x4b/0x1be
load_module+0x201a/0x2590
sys_init_module+0xfd/0x120
do_int80_syscall_32+0x6a/0x1a0
restore_all+0x0/0x8d
该警告还将提供额外的信息和一个潜在的不安全加锁场景:
可能的不安全加锁场景:
CPU0
----
lock(lock#4);
<Interrupt>
lock(lock#4);
*** DEADLOCK ***
1 lock held by ksoftirqd/0/9:
#0: (ptrval) (/home/tavi/src/linux/tools/labs/skels/./debugging/locking2/locking2.c:13){+.-.}, at: call_timer_f0
stack backtrace:
CPU: 0 PID: 9 Comm: ksoftirqd/0 Tainted: G O 4.19.0+ #4
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.10.2-1ubuntu1 04/01/2014
Call Trace:
dump_stack+0x66/0x96
print_usage_bug.part.26+0x1ee/0x200
mark_lock+0x5ea/0x640
__lock_acquire+0x4b4/0x17a0
lock_acquire+0x93/0x190
_raw_spin_lock+0x39/0x50
timerfn+0x25/0x60 [locking2]
perf¶
- 性能计数器,跟踪点,kprobes,uprobes
- 硬件事件: CPU 周期,TLB 缺失,缓存缺失
- 软件事件: 页面错误,上下文切换
- 收集回溯信息(用户空间 + 内核空间)
其他工具¶
- ftrace
- kprobes
- sparse
- coccinelle
- checkpatch.pl
- printk
- dump_stack()