对称多处理
- 内核并发
- 原子操作
- 自旋锁
- 缓存抖动
- 优化自旋锁
- 进程和中断上下文同步
- 互斥锁
- 每个 CPU 的数据
- 内存排序和屏障
- 读-拷贝 更新(RCU)
void release_resource()
{
counter--;
if (!counter)
free_resource();
}
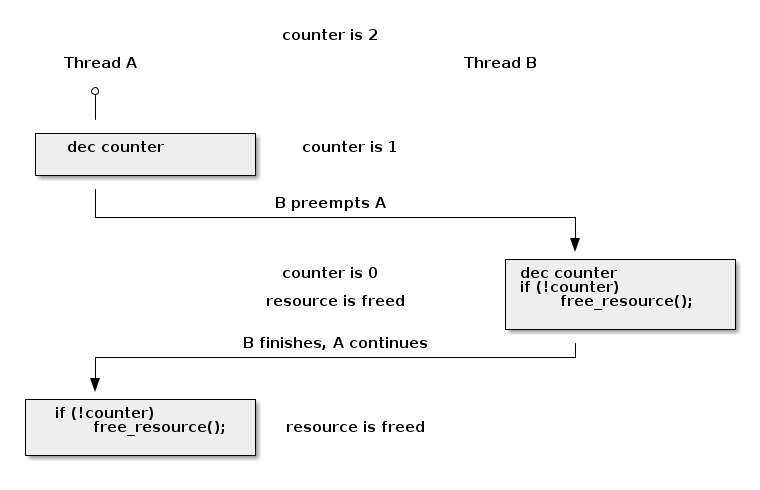
atomic_inc() (原子递增), atomic_dec() (原子递减), atomic_add() (原子加法), atomic_sub() (原子减法)atomic_dec_and_test() (原子递减并测试), atomic_sub_and_test() (原子减法并测试)test_bit() (测试位), set_bit() (设置位), change_bit() (修改位)test_and_set_bit() (测试并设置位), test_and_clear_bit() (测试并清除位), test_and_change_bit() (测试并修改位)atomic_dec_and_test() 来实现资源计数器的释放void release_resource()
{
if (atomic_dec_and_test(&counter))
free_resource();
}
#define local_irq_disable() \
asm volatile („cli” : : : „memory”)
#define local_irq_enable() \
asm volatile („sti” : : : „memory”)
#define local_irq_save(flags) \
asm volatile ("pushf ; pop %0" :"=g" (flags)
: /* no input */: "memory") \
asm volatile("cli": : :"memory")
#define local_irq_restore(flags) \
asm volatile ("push %0 ; popf"
: /* no output */
: "g" (flags) :"memory", "cc");
spin_lock:
lock bts [my_lock], 0
jc spin_lock
/* 临界区 */
spin_unlock:
mov [my_lock], 0
**bts dts, src**——位测试并设置;它将来自 dts 内存地址的第 src 位复制到进位标志位(carry flag),然后将其设置为 1:
CF <- dts[src]
dts[src] <- 1
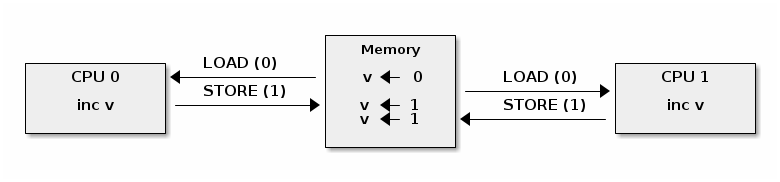
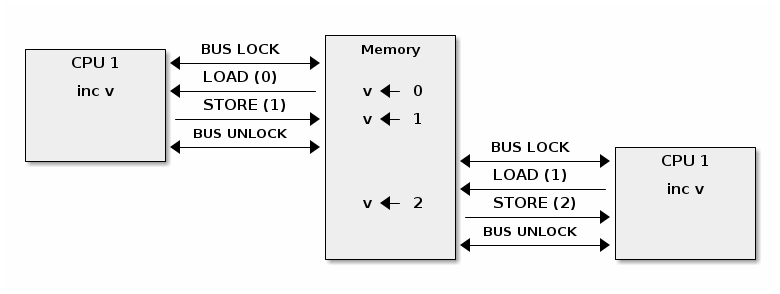
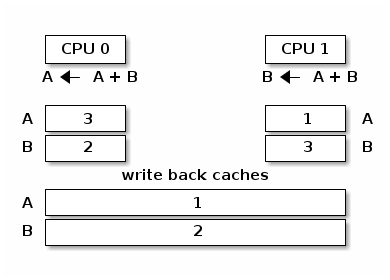
当多个处理器核心试图读写同一内存时,会发生高速缓存抖动,导致过多的高速缓存未命中。
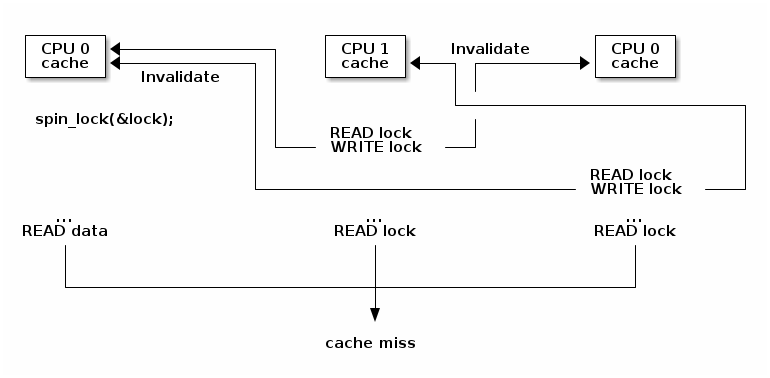
由于自旋锁在锁争用期间不断访问内存,高速缓存抖动很常见,这是由高速缓存一致性的实现方式造成的。
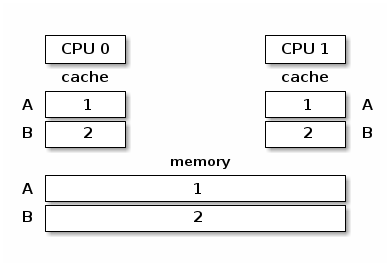
缓存嗅探协议较为简单,但当核心数超过 32-64 时性能表现较差。
目录协议的缓存一致性协议能够更好地扩展(可达数千个核心),非一致性存储访问(NUMA)系统中通常使用的就是目录协议。
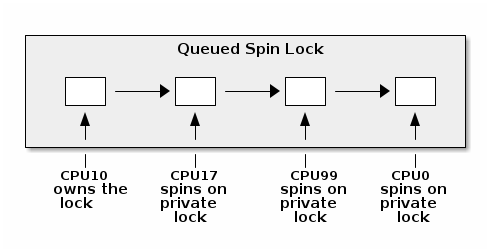
spin_lock:
rep ; nop
test lock_addr, 1
jnz spin_lock
lock bts lock_addr
jc spin_lock
spin_lock_irqsave() 和 spin_lock_restore() 结合了这两个操作)spin_lock_bh() (将 local_bh_disable() 和 spin_lock() 结合起来) 和 spin_unlock_bh() (将 spin_unlock() 和 local_bh_enable() 结合起来)spin_lock() 和 spin_unlock() (如果与中断处理程序共享数据,则使用 spin_lock_irqsave() 和 spin_lock_irqrestore())
抢占是可配置的:如果激活,它提供更低的延迟和响应时间,而如果停用,它提供更好的吞吐量。
抢占被自旋锁和互斥锁禁用,但也可以手动禁用(通过核心内核代码)。
#define PREEMPT_BITS 8
#define SOFTIRQ_BITS 8
#define HARDIRQ_BITS 4
#define NMI_BITS 1
#define preempt_disable() preempt_count_inc()
#define local_bh_disable() add_preempt_count(SOFTIRQ_OFFSET)
#define local_bh_enable() sub_preempt_count(SOFTIRQ_OFFSET)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK))
#define in_interrupt() irq_count()
asmlinkage void do_softirq(void)
{
if (in_interrupt()) return;
...
mutex_lock() 捷径void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (!atomic_long_cmpxchg_acquire(&lock->owner, 0UL, curr))
return true;
return false;
}
mutex_lock() 慢路径...
spin_lock(&lock->wait_lock);
...
/* 添加等待的任务到等待队列尾部 (FIFO): */
list_add_tail(&waiter.list, &lock->wait_list);
...
waiter.task = current;
...
for (;;) {
if (__mutex_trylock(lock))
goto acquired;
...
spin_unlock(&lock->wait_lock);
...
set_current_state(state);
spin_lock(&lock->wait_lock);
}
spin_lock(&lock->wait_lock);
acquired:
__set_current_state(TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current);
spin_lock(&lock->wait_lock);
...
mutex_unlock() 快速路径void __sched mutex_unlock(struct mutex *lock)
{
if (__mutex_unlock_fast(lock))
return;
__mutex_unlock_slowpath(lock, _RET_IP_);
}
static __always_inline bool __mutex_unlock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (atomic_long_cmpxchg_release(&lock->owner, curr, 0UL) == curr)
return true;
return false;
}
void __mutex_lock_slowpath(struct mutex *lock)
{
...
if (__mutex_waiter_is_first(lock, &waiter))
__mutex_set_flag(lock, MUTEX_FLAG_WAITERS);
...
mutex_unlock() 慢速路径...
spin_lock(&lock->wait_lock);
if (!list_empty(&lock->wait_list)) {
/* 获得等待队列的第一个条目 */
struct mutex_waiter *waiter;
waiter = list_first_entry(&lock->wait_list, struct mutex_waiter,
list);
next = waiter->task;
wake_q_add(&wake_q, next);
}
...
spin_unlock(&lock->wait_lock);
...
wake_up_q(&wake_q);
| C code | Compiler generated code |
a = 1;
b = 2;
|
MOV R10, 1
MOV R11, 2
STORE R11, b
STORE R10, a
|
rmb(),smp_rmb()) 用于确保没有读操作越过屏障;也就是说,在执行屏障之后的第一条指令之前,所有的读操作都已经完成wmb(),smp_wmb()) 用于确保没有写操作越过屏障mb(),smp_mb())用于确保没有读操作或写操作越过屏障
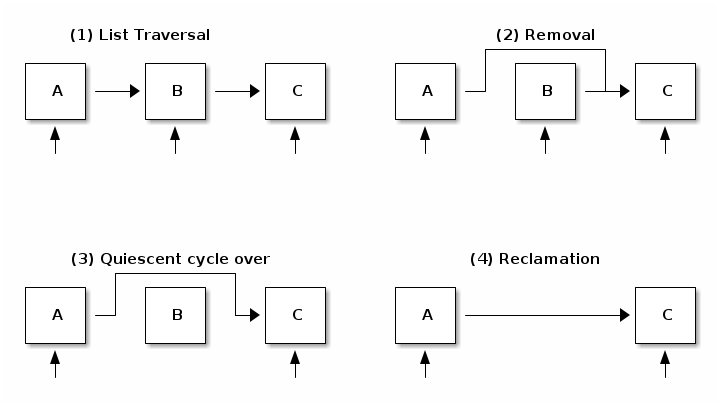
/* 列表遍历 */
rcu_read_lock();
list_for_each_entry_rcu(i, head) {
/* 不允许休眠、阻塞调用或上下文切换 */
}
rcu_read_unlock();
/* 列表元素删除 */
spin_lock(&lock);
list_del_rcu(&node->list);
spin_unlock(&lock);
synchronize_rcu();
kfree(node);
/* 列表元素添加 */
spin_lock(&lock);
list_add_rcu(head, &node->list);
spin_unlock(&lock);